

Build self-improving agent system with Fable 5 in 14 steps : loops, dynamic workflows, routines
Most people are using Claude Fable 5 like Sonnet 4.6 with a bigger context window. They prompt it. It works for 5 minutes. They close the tab.
9 out of 10 users have never run an agent system that compounds - where every run leaves the next run smarter, every state file accumulates, every skill sharpens.
Fable 5 was built to run for days. You’re using it for minutes. This is the 14-step roadmap to build the self-improving system Fable 5 was designed for.
Follow my Substack to get fresh AI alpha: movez.substack.com
Claude Fable 5 launched June 9, 2026 - the first publicly available Mythos-class model, the tier Anthropic put one rung above Opus.

This is the 14-step roadmap to build the self-improving system Fable 5 was designed for - sourced from Anthropic engineering posts, the team’s public experiments, and verified against the launch documentation as of June 2026.
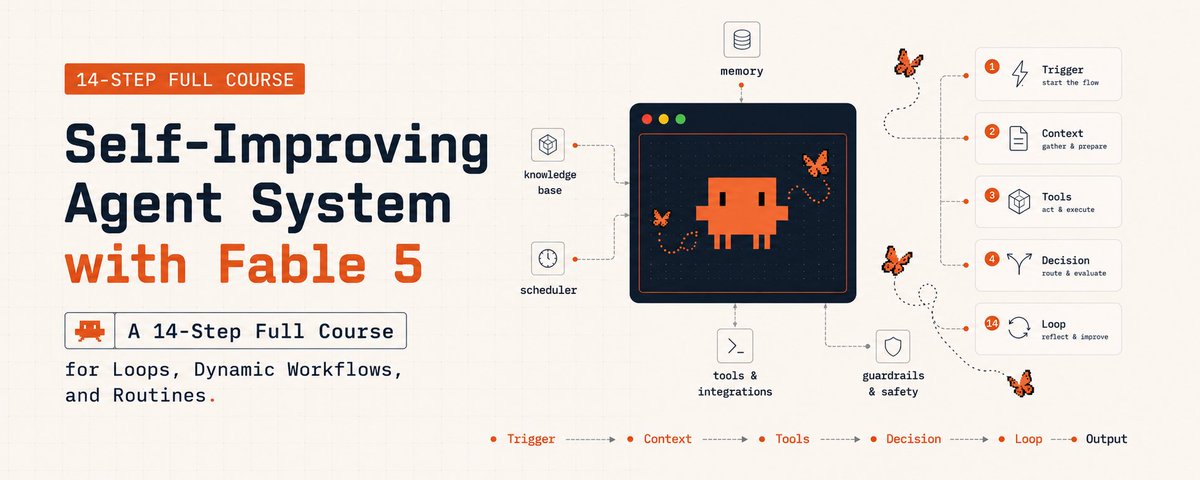
Three tiers: what Fable 5 actually unlocks, the three primitives that make it compound (loops, dynamic workflows, routines), and the self-improvement layer that turns it into a system.

14 steps. 3 tiers. Stop prompting. Start building a system that compounds.
PART 1 · What Fable 5 actually unlocks
01. Fable 5 is a Mythos-class model. Days-long autonomy is the headline.
Claude Fable 5 launched June 9, 2026 as the first publicly available Mythos-class model - the tier Anthropic introduced one rung above Opus.

Mythos Preview shipped in April through Project Glasswing to a handful of critical-infrastructure partners; Fable 5 is the version Anthropic considered safe for general release, with built-in safety classifiers that decline requests in high-risk areas.
Mythos 5 (without those classifiers) remains Glasswing-only.
What Fable 5 actually does that previous Claude models couldn’t sustain, from Anthropic’s launch documentation:
The pricing matches the tier: $10 per million input tokens, $50 per million output tokens, with the existing 90% input token discount for prompt caching.
Available on Claude API, AWS, Amazon Bedrock, Vertex AI, Microsoft Foundry, and the consumption-based Enterprise plan. This is not a subscription model. Heavy use earns its own bill.
02. Self-improving is not self-learning.
The phrase “self-improving agent system” gets thrown around carelessly. The version that’s real and the version that’s hype are very different things, and the gap is worth understanding before you build anything.

Self-improvement, in this sense, is a property of the system you build. Fable 5 has the raw capability - long context, sub-agent delegation, vision self-check, days-long stamina - that turns the environment-feedback loop into something that actually compounds run over run.
Anthropic’s engineering team puts it directly:
“Rather than directly prompting and steering Fable 5, it’s often better to design loops that let the model self-correct in response to environment feedback (e.g., /goal or Outcomes) and manage its own context (e.g., via memory).”
03. The compound stack: four layers, one feedback loop.
Figure 1 at the top of this article shows the architecture in one diagram. Read it from the bottom up - that’s the order the system gets built, and the order the leverage compounds.
The reason this architecture compounds: every output from layer 1 flows up through layer 4, where it gets graded, distilled, and written back to layer 3. Tomorrow’s run at layer 1 inherits the sharpened memory and refined Skills from yesterday. The model is stateless; the system around it isn’t.
04. When to use Fable 5 vs Opus 4.8 vs Sonnet 4.6. The cost-capability matrix.
Fable 5 costs ~5× what Opus 4.8 does per token. Not every step in a self-improving system needs the top tier. The teams running this in production route by task complexity, not by default:

The cost pattern that makes a self-improving system economical, used by teams running this in production: orchestrator on Fable 5, workers on Sonnet 4.6, graders on Haiku 4.5, fallback to Opus 4.8 on classifier blocks. Same pattern Anthropic engineers use internally.
PART 2 · The three Primitives
05. /goal vs Outcomes. Two implementations of the same idea.
The Anthropic Claude Code team publishes two near-identical primitives for goal-driven loops one in each harness.
They share the same shape: an independent grader checks the work, a not-met verdict starts the next iteration, the loop exits when the grader passes.
The implementations differ in surface details that matter for which you use.

The decision rule between them is short:
Both share the structural move that makes them work: the agent that wrote the code is not the agent that grades it. We go deeper on why that matters in step 6.
06. Verifier sub-agent beats self-critique.
Anthropic engineer Prithvi Rajasekaran wrote a piece on the engineering blog showing models have a hard time self-critiquing their own outputs. The Claude Code team confirmed this empirically with Fable 5:
“We’ve found that a verifier sub-agent tends to outperform self-critique with Fable 5"
The mechanism is structural, not about “trying harder.” A model evaluating its own output sees its own reasoning trail and prefers conclusions consistent with what it already wrote.
A separate model evaluating the same output sees only the artifact and the rubric. The verifier has no skin in the maker’s game.

What the chart actually shows, beyond the headline numbers:
The takeaway for system design: Fable 5 with an independent verifier explores larger hypothesis spaces and recovers from negative intermediate results. Without the verifier, the same model has nothing forcing it past the first “good enough.”
07. Dynamic Workflows compose self-correction patterns.
Dynamic Workflows shipped in Claude Code on May 28, 2026.
The idea: Claude writes its own JavaScript harness on the fly - a file with agent(), parallel(), and pipeline() primitives, plus standard JS to process the data flowing between them. The harness is custom-built for the task, not generic.
For self-improving systems with Fable 5, three of the six documented Dynamic Workflow patterns earn their place:
The two patterns that don’t typically appear in self-improving systems but are worth knowing: classify-and-act (route the task to the right model based on a classifier) and tournament (pairwise comparison for taste-based ranking). The first is useful for model routing (step 4).
The second is rare in coding loops but useful for design or naming tasks.
08. Worktrees for parallel safety. Days-long Fable 5 sessions, no file collisions.
The moment a self-improving system spawns more than one agent, files start colliding. Two agents writing the same file is the same problem as two engineers committing to the same lines without talking first.
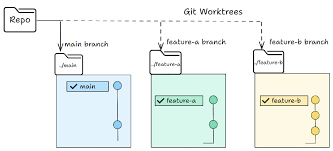
A git worktree fixes it - a separate working directory on its own branch sharing the same repo history, so one agent’s edits literally cannot touch the other’s checkout.
For self-improving systems where Fable 5 spawns sub-agents to verify or specialize, worktrees are non-optional:
In Claude Code, worktrees are exposed three ways: git worktree directly, a --worktree flag to open a session in its own checkout, and an isolation: worktree setting on subagents so each helper gets a fresh checkout that cleans itself up after the session ends.
09. Routines for days-long orchestration. Laptop closed. Fable 5 working.
Routines launched April 14, 2026 in research preview. They’re saved Claude Code configurations - a prompt, repositories, connectors, permissions - that run on Anthropic-managed cloud infrastructure on a trigger.
Your laptop can be off. The run still happens.

For Fable 5 specifically, Routines are the trigger layer that earns the model’s capability. Anthropic measures Fable 5’s “days at a time” on Claude Managed Agents - a hosted sandbox with full tools and no local machine constraint.
The Parameter Golf experiment ran for up to 8 hours on 8×H100 GPUs. That class of run doesn’t happen on your laptop.
The three Routine trigger types, mapped to self-improvement patterns:
PART 3 · The Self-Improvement Layer
10. The 5-stage memory progression.
The single most useful framing for what “agent memory” means in practice comes from the Anthropic team’s Continual Learning Bench 1.0 experiment. Effective use of memory requires a progression of five stages. Each stage is a structural move; each model exits the progression at a different point.

The measured difference between models on a SQL exploration task from the Continual Learning Bench, each model with memory provided:
11. The state file. Where memory actually lives.
The 5-stage progression is the mental model. The state file is where the model writes each stage’s output. For Fable 5 running in Claude Managed Agents, memory is a mounted filesystem that survives between sessions; in Claude Code locally, a markdown file or a Linear board does the same job.
The structure of a state file that actually supports the 5-stage progression:
The file has five sections matching the five stages. Verified facts is stage 3 output - things the agent stopped guessing about. General rules is stage 4 - distilled rules that apply beyond the specific case. Open failures is stages 1–2 work in progress. Lessons learned is more stage 4 output.
Last session is the resume pointer for stage 5.
Two operational rules that decide whether this file actually compounds or just grows:
12. Skills that compound. Write the lesson into the Skill, not just the chat.
STATE.md is for project memory. Skills are for procedural memory - the “how to do this kind of thing” that should apply across projects.
The compounding pattern: after any non-trivial failure, write the lesson into the Skill itself. The Skill gets sharper every time the system runs.

A Skill that’s been compounding for two weeks looks different from a fresh one. New sections appear: known failure modes, rules that came out of post-mortems, anti-patterns observed in production.
The Skill is no longer a static set of instructions; it’s an accumulating record of what the team has actually learned.
The compounding contract: every confirmed lesson goes into a Skill, not just STATE.md. STATE.md is project-scoped and dies with the project. Skills live in ~/.claude/skills/ and travel with you.
Two weeks of disciplined writing produces a Skill that materially outperforms whatever Fable 5 would derive from scratch on a fresh project.
13. Self-verification via vision. Fable 5 checks its own UI against the goal.
One of the headline capabilities Anthropic ships with Fable 5 is “uses vision to check outputs against goals.” This sounds abstract until you see what it actually replaces: the human eyeballing a screenshot to confirm the UI looks right.
Fable 5 does that step itself, in the loop, before declaring done.
The pattern in production:
This pattern is what Anthropic measured in the Parameter Golf experiment under the same harness: Fable 5 looked at training charts (visual artifact) and decided whether the curve matched the criterion.
No human in the loop reading the chart. The verifier read the chart.
14. The Mythos safety boundary. What Fable 5 won’t do, and how to design around it.
he last step is the one most easily skipped on day one and most expensive to learn the hard way.
Fable 5 ships with built-in safety classifiers that decline to respond in specific high-risk domains - cybersecurity vulnerability research, biology, chemistry, and model distillation. In those domains, Anthropic falls Fable 5 back to Claude Opus 4.8 automatically. This is documented; it’s not a bug.
What this means for a self-improving system that runs autonomously:
The general design principle: treat the safety boundary as a known fallback, not as a failure mode. A self-improving system that ships with explicit handling of the boundary stays robust as the classifier evolves. A system that ignores it produces silent regressions when Anthropic updates the policy.
§ The mistakes that keep Fable 5 at 10% of its potential
Conclusion:
Fable 5 isn’t a faster chat tool. It’s the substrate for a system that compounds.
The first publicly available Mythos-class model didn’t ship to be prompted faster. It shipped to be the orchestrator of a self-improving system you build around it.
The capability headlines - days-long sessions, sub-agent delegation, vision self-check, accumulated memory - only earn their pricing if the system around the model is doing its job.
The Anthropic team’s own experiments make the gap visible. Parameter Golf: Fable 5 with an independent verifier explored larger architectural changes and pushed through negative intermediate results to land ~6× more improvement than Opus 4.7.
Continual Learning Bench: Fable 5 with memory completed the full 5-stage progression with 73% verification coverage, against Opus 4.7’s 17%. The model is the same in both halves of every comparison. The system around it is what changed.
Pick one layer of the compound stack you weren’t doing - probably the verifier sub-agent (step 6), the state file (step 11), or vision-verify (step 13) - and add it tomorrow. Then the next.
Self-improvement is a property of the system, not the model. Build the system.