

How to build a second brain with Fable 5

I'm going to show you, step by step, how to turn Fable 5 into a machine that knows your business inside out... and ships outputs that look nothing like what everyone else is getting
the tool is a second brain built in Obsidian, and a small group of people is already running one... exactly the same model, a world of difference in every output

the smartest model on the market ships average work all day for one reason: it knows nothing about you
no context on your business, your audience, your past decisions... so it guesses, and guesses read generic
plug it into your own knowledge base and the same model becomes a different machine
the code follows your architecture, the content sounds like you, the writing stands on research you own... and you see it from day one
and this holds for ANY workflow you run: coding, marketing, content, sales, research
running an AI agent without a second brain is wasting your time... and the gap only widens, because every file the brain gains makes every future run smarter, forever
i run this exact machine every day... it sits behind every article, every guide, and every product i ship
this is the full system... what a second brain really is, the folder structure the agent navigates on its own, how to fill it with goals, keep it alive with loops, run a real research machine on top of it, read it without burning money, and wire it into everything you build
if you want to learn how to get the most out of Fable 5 and how to make money with it, that's what the real time AI ops community is for: weeklyaiops.com
same model, different league
here are the numbers behind that claim
in accounting, a model working without the client's history lands around 70% accuracy
give it the client's transaction history and it starts at 85% and climbs past 90%
nothing about the model changed, the knowledge did
writing works the same way
a mid-tier model with a well-built voice profile produces more recognizable output than Fable 5 with no profile at all
the files carry more of the result than the model tier does
and the model itself rewards this harder than anything before it
Anthropic's own testing had Fable play a full deck-building game with file-based memory, and it improved three times more than the previous flagship
one game, tested by the vendor, replicated by nobody yet... but the move the number points at costs you a folder of markdown, so you take it either way
before we build, i have to tell you something: the model doesn't magically find everything in your notes
what it does is act on knowledge that lives outside the conversation, and cite where every piece came from
the memory is yours, on your disk, in plain text you can open and read
give it a few weeks and the agent starts citing decisions you forgot you made
the first question is where this memory should live
the answer costs nothing and you might already have it installed
what Obsidian is, in one minute
Obsidian is a free app that sits on top of a folder of markdown files on your computer
no database, no cloud lock-in... your notes are plain text files you own, and the app is just a beautiful window into them
you only need two of its features:
> [[wikilinks]]: type double brackets around any note's name and the two notes are now connected
> the graph view: Obsidian draws every note as a dot and every link as a line, so you see your knowledge as a web
and it fits agents perfectly: because the vault is just a folder, Fable works on it directly through Claude Code, the terminal app the model runs in on your machine
no plugin, no connector, no special setup... the agent reads and writes markdown files, Obsidian shows you what changed
you use the app, the agent uses the folder, both are looking at the same brain
and before you brace for a big project: the starter version of everything in this article takes about an hour, and once the reading rules are set it runs on pennies... the money part gets its own section
what separates a brain from a pile of files is the structure... and structure is where almost everyone gets it wrong
the structure: four pieces, nothing else
the thinking comes from karpathy's llm-wiki idea: treat your knowledge base like a codebase
Obsidian is the editor, the model is the programmer, the wiki is the code
after digging through the setups people run in public, the repos, the viral templates, the failure threads, four pieces kept showing up:
> raw - everything you capture goes here untouched: articles, transcripts, call notes, competitor pages... read-only history, the agent never rewrites it
> entities - one page per concrete thing: a client, a competitor, a tool, a person
> concepts - one page per idea: a strategy, a pattern, a lesson
> INDEX.md - the front door: every page listed with a one-line description, so the agent knows what exists without opening everything
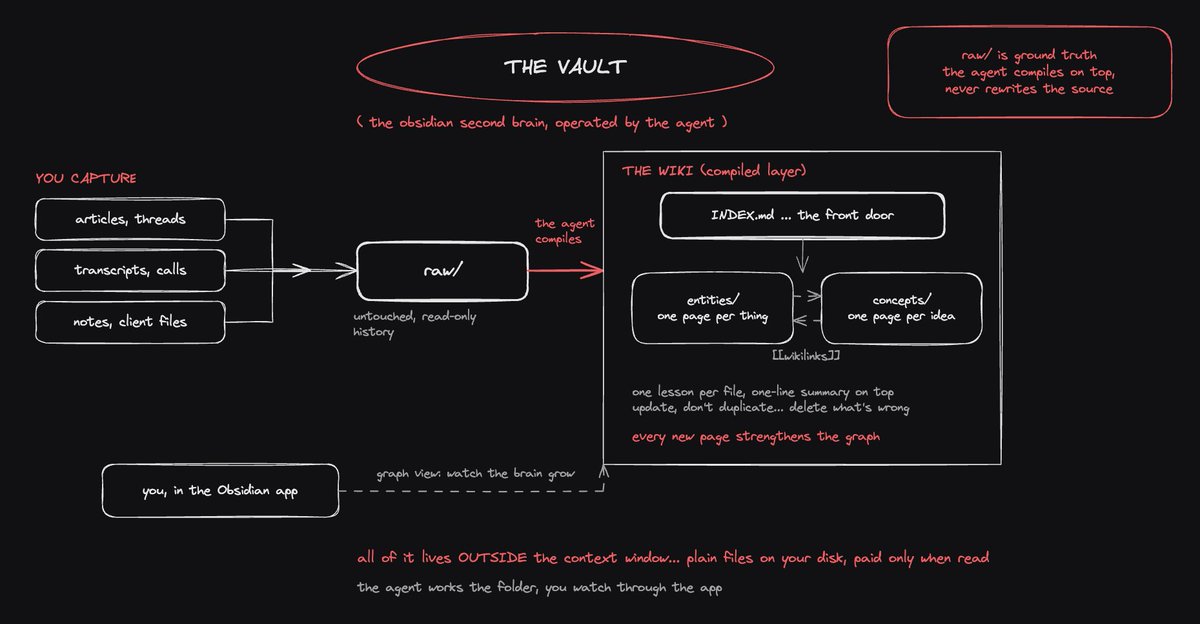
the agent's job is compiling: it reads new material in raw/ and updates the entity and concept pages, linking them as it goes
and the writing rules are simple enough to fit in four lines:
> one lesson per file, with a one-line summary at the top
> update the existing page instead of creating a duplicate
> delete notes that turn out to be wrong
> keep raw sources and compiled pages separate, always
why raw/ stays untouched: when the same agent reads and rewrites the same notes over and over, details blur and errors compound
the raw folder is your ground truth, and the wiki keeps getting smarter on top of it
and the pages are only half the value... the links between them are where the real edge hides
knowledge graphs: why this gets better as it grows
every [[link]] the agent writes between two pages is an edge in a graph
this is the part that separates a vault from a pile of notes: a search-based knowledge base gets noisier as it grows, because more files means more junk in every search
a linked wiki gets stronger as it grows, because every new page connects into the web and makes the surrounding pages more useful
when the agent needs to answer something, it doesn't scan everything... it walks the links
from the client's page to the campaign concept to the competitor page, following connections the way you'd follow your own memory
karpathy's own vault sits around 100 articles and 400,000 words, all compiled by the model, all connected
open the graph view after two weeks of this and you'll see your business as a living map... that picture alone changes how you think about what you know
so how do you fill it without spending a month copy-pasting?
populate it with goals
the first move is a backfill, and Fable's goal system was built for exactly this job
/goal in Claude Code lets you write one finish line, and the model keeps working on its own while a second, smaller model reads along as the judge and confirms when the line is crossed
the trick is the judge only sees what's in the conversation, so the goal must demand proof it can read:

feed raw/ with what you already own before you run it: old chat transcripts, bookmarked threads, your notes app export, client folders, past research
then walk away, and come back to a compiled brain
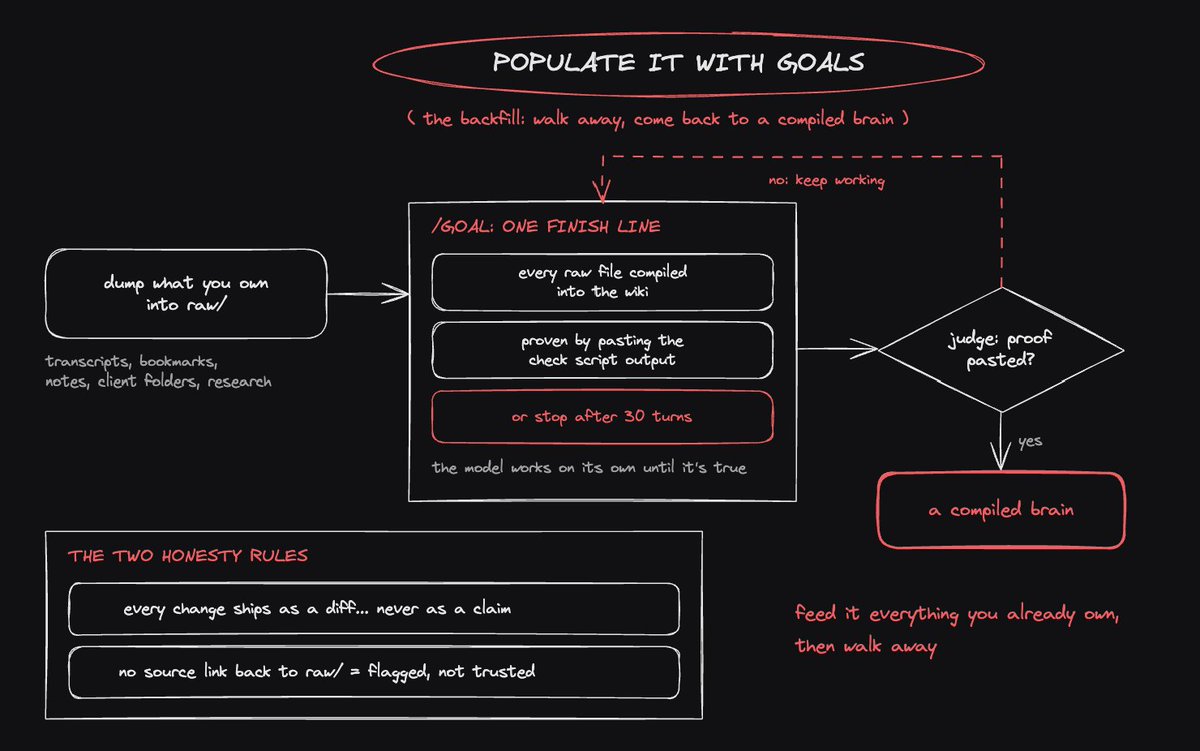
two rules keep the backfill honest:
> every change ships as a diff, the exact before-and-after lines, never as a claim... if the agent says it updated a page, the diff proves it
> a page without a source link back to raw/ gets flagged, not trusted
the backfill hands you a compiled brain... keeping it alive is a different job, and it's the one everybody skips
keep it alive with loops
a second brain that only grows when you remember to feed it is a dead brain in three weeks
so the maintenance runs on schedules, not on memory:
> after every session: a hook, a small script that fires on its own when a session ends, mines what just happened... decisions made, mistakes caught, patterns confirmed, written into the vault as dated notes... work you already did becomes memory without you filing anything
> every night: a compile pass on a cheap model reads the day's new raw material and updates the wiki pages... routine work, routine tier
> every week: a lint pass hunts contradictions, duplicate pages, and dead links... this is the loop that keeps the graph clean, and it exists because unmaintained wikis rot
> every week: one synthesis pass on the big model reads across the whole vault and writes what changed this week, what's drifting, what deserves attention
that last one is the only pass where the premium model earns its seat
everything else runs on the cheap tier, because updating notes is routine work and routing routine work to Fable is how people burn money for nothing
maintenance keeps the vault clean... but where does the material that makes it valuable come from?
the research workflow that feeds it
this is where the vault stops being storage and becomes an edge, and it's also the step where garbage usually gets in
the default AI research is one prompt to a chatbot, and the answer dies in the scrollback
worse, it's built on stale knowledge... in AI, advice from six months ago is often actively wrong, and the real practitioner layer, what people are running right now, what breaks, what works, lives on socials, not in official docs
so the research machine works like this:
> one question goes in, and it gets split into 3-5 sub-questions
> parallel agents fan out, each searching a different surface: socials for the practitioner layer, the web for documentation and pricing, scrapers pulling the full text of everything worth reading
> every finding becomes a receipt: the claim, the source link, the date
> then the gate that makes it real: a skeptic agent attacks every claim and tries to kill it... single-source hype gets labeled, contradictions get surfaced, only survivors pass
> verified findings land in the vault as pages, each one dated and linked, each one carrying an expiry date so stale knowledge announces itself
and the exact stack i run it on:
> last30days powered by ScrapeCreators (scrapecreators.com): one skill that sweeps reddit, X, youtube, instagram and tiktok for the last 30 days of practitioner talk on any topic
> the official X MCP (api.x.com/mcp): live posts, threads and bookmarks straight from the source
> youtube transcripts with yt-dlp (github.com/yt-dlp/yt-dlp): any walkthrough or tutorial becomes text the agent can mine
> instagram and tiktok content through ScrapeCreators, because short-form is where new workflows surface first
> Perplexity deep research (perplexity.ai): the cited long-read pass across the web
> Firecrawl (firecrawl.dev): pulls the full text of every page worth keeping, as clean markdown
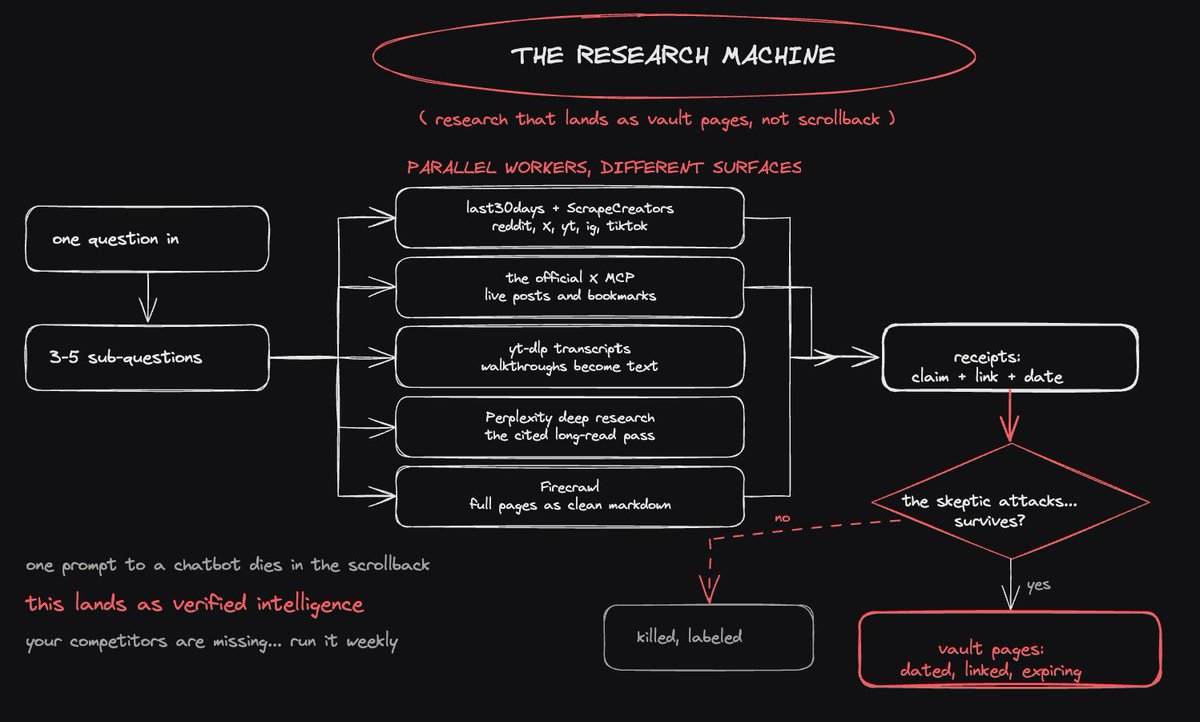
the skeptic is what separates research from rumor collection: fresh-context checkers outperform a model reviewing its own work, so the attack always comes from an agent that didn't do the research
run this on your niche once a week and the vault fills with verified, dated, sourced intelligence your competitors are missing
all of it worthless, though, if reading the vault costs more than it returns
read it without burning money
a vault only works long-term if reading it is cheap, and this is the leak in almost every setup
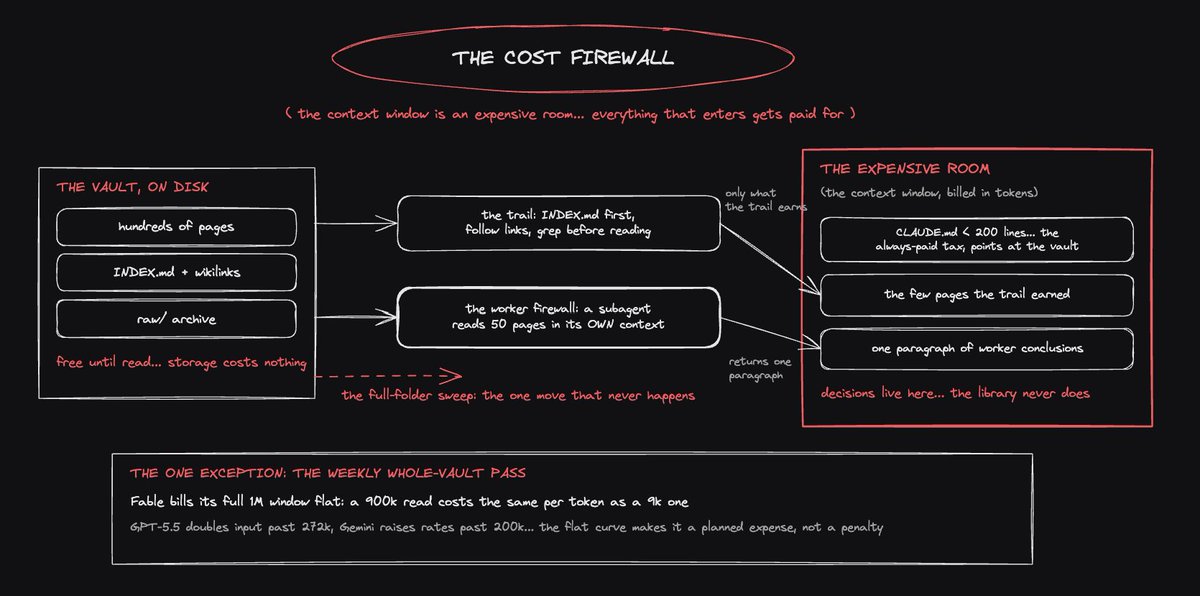
the mental model: the context window is an expensive room, and everything that enters it gets paid for in tokens... the chunks of text every AI bill is counted in
> your CLAUDE.md, the instruction file the agent reads at the start of every session, loads automatically every single time... that's the always-paid tax... keep it under 200 lines pointing at the vault, never containing it
> everything else is pay-per-read: the agent checks INDEX.md, follows links, greps for keywords, and opens only the pages the trail points at... a full-folder sweep is the one move that never happens
> for big questions, send a worker: a subagent reads fifty pages in its own separate context and returns one paragraph of conclusions to your session... the expensive room holds decisions, not the library
wire it into everything you build
a vault that only stores things is a filing hobby... this one feeds every project you run
point any project at it with three lines in that project's CLAUDE.md:
and the outputs change immediately:
> marketing: campaign briefs grounded in your actual audience pages and competitor history, not generic personas
> content: drafts that cite your own past research and match your voice profile
> coding: the agent keeps living architecture notes per project in the vault, so no session ever starts blind
> client work: every deliverable opens with the full relationship history behind it
then the second half: the vault itself becomes product
the research pages become articles and guides, the concept pages become courses, the client pages become case studies... you're not creating from a blank page anymore, you're packaging what the machine already verified
the warning that saves your vault: sync is where vaults die
run a single sync system... if the agent writes files while iCloud syncs them, you get conflicted copies and scrambled folders
git, the save-point system programmers use, works as the checkpoint layer... it locks in a version only when you tell it to, and that setup survives
the card
the whole build, in order... copy this:
> create the vault: raw/, entities/, concepts/, and an INDEX.md
> write the four rules into your CLAUDE.md: one lesson per file, update don't duplicate, delete what's wrong, never touch raw/
> dump everything you own into raw/: transcripts, bookmarks, notes, client folders
> run the /goal backfill with pasted proof and a stop clause
> schedule the loops: session hook, nightly compile on the cheap tier, weekly lint, one premium synthesis pass
> run the weekly research sweep: fan out, let the skeptic attack, land survivors as dated pages
> add the three knowledge lines to every project's CLAUDE.md
ihe model in the driver's seat will change again... the vault survives every swap, and the feedback written into it makes it smarter every week no matter who's driving
the smallest version takes an hour: one folder, ten files about your business, and an agent told to read them first
your outputs will tell you the rest
join the best AI community in the world: weeklyaiops.com