

The Economics Of A Gigawatt
Hyperscaler[1] capital spending has reset higher again. Following recent earnings, guidance for 2026 capital expenditure (capex) across Amazon, Microsoft, Alphabet, and Meta has moved above $700 billion in aggregate. The signals inspiring the accelerated spending look strong. AI Agents have driven an inflection in demand, which in turn is fueling a need to scale compute infrastructure faster. Cloud revenues in Q1 2026 impressed: Google Cloud revenue grew 63%, Amazon Web Services (AWS) grew 28% at its fastest pace in 15 quarters, and Microsoft Azure grew 39%.
Despite these growth rates, many have raised eyebrows at this stratospheric investment, wondering if these companies are overbuilding. To understand whether the physical infrastructure required to serve AI demand can earn attractive returns, investors must analyze both the costs and revenue generating potential of AI data centers.
Building A Gigawatt Data Center

Estimates from Epoch AI suggest a gigawatt-scale facility filled with Nvidia GB200s breaks down as follows: $11.8 billion for facility, land and utility substations; $21 billion for AI servers, and $4.9 billion for networking and other IT infrastructure. That puts the upfront total build near $38 billion. Opting for behind the meter power generation, increasingly common to accelerate project development, would add an estimated $3 billion of cost, per Crusoe’s Chase Lochmiller. Operating expenses (opex) are relatively small, mostly electricity, at $0.9 billion annually per Epoch’s estimates
In today’s high demand environment, buildout costs are not constant. JLL estimates that average global data center shell construction costs increased from $7.7 million per Megawatt (MW) in 2020 to $10.7 million per MW in 2025, with another increase expected in 2026. Cushman & Wakefield reports that key electrical and mechanical inputs such as switchgear, uninterruptible power supply (UPS) systems, generators, transformers, and chillers have risen roughly 40%-50% since Q3 2021.
While rising costs per gigawatt are important to watch, improving efficiency at both the chip and model layers have been delivering returns on infrastructure investment that are increasingly favorable over time, shifting value accrual from the chip companies and data center builders to the cloud operators and model owners, as detailed by SemiAnalysis. This dynamic occurs because each generation of chip typically has better performance per watt that its predecessor, and because algorithmic advances allow AI models to more efficiently leverage compute resources over time.
AI Infrastructure-As-A-Service (IaaS) Economics
The AI cloud business model is straightforward on the surface: raise capital, secure power, buy the latest accelerators, and rent scarce compute to customers that need dedicated capacity. The key variables are GPUs supported by the facility, utilization, and contracted rental price per GPU-hour, while the primary constraints are access to powered data center shells, GPU allocations, and affordable financing. Under the surface, cluster performance tuning plays a significant role in end-user economics, and thus willingness to pay, while supplier relationships and customer contracts play a huge role in access to chip supply and financing, a dynamic which benefits the hyperscalers and scaled neoclouds[2] like Coreweave, Nebius, and Crusoe.
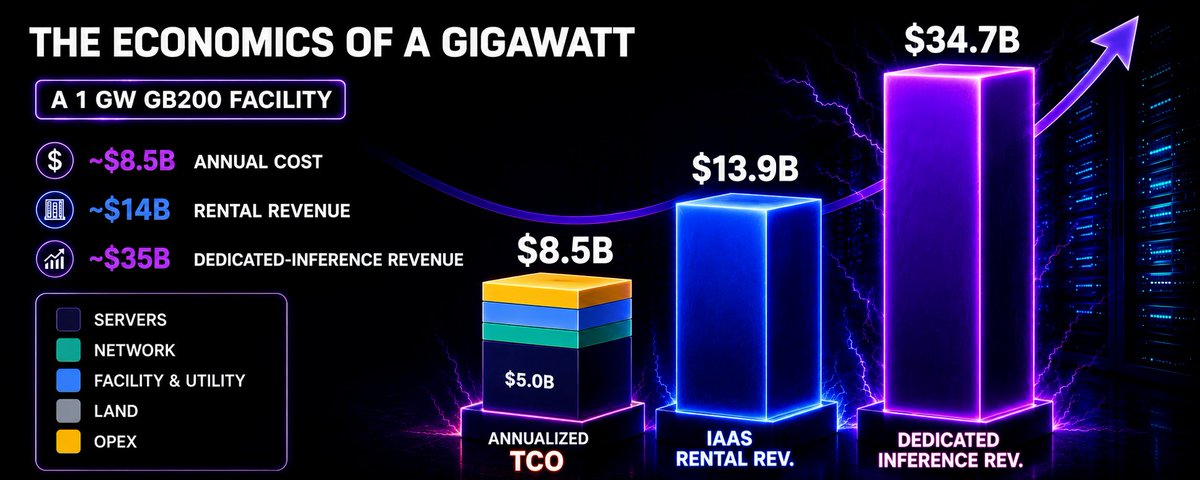
The below example helps to elucidate the revenue potential of renting out a gigawatt-sized fleet of GB200 chips. Public InferenceX modeling assumptions use a three-year GB200 rental input of $3.30 per GPU-hour. Applying that rental input to roughly 480,000 GB200-class GPUs that can fit into 1 GW critical IT power, implies ~$14 billion of annual GPU-rental potential, assuming the GPUs are rented on a 1+ year contract, which is most common for leading edge chips coming online today.

To compare revenue with cost, an annualized Total Cost of Ownership (TCO) framework is more useful than upfront capex alone. If the facility depreciates over 14 years and the IT equipment depreciates over 5 years, annual depreciation is roughly $1.4 billion for the facility and $6.2 billion for IT equipment. Adding $0.9 billion of annual OPEX yields a roughly $8.5 billion annualized cost base. Against $14 billion of modeled IaaS revenue, the spread can be attractive before additional financing costs, taxes, and residual value assumptions are applied.

The above spread indicates roughly $5.4 billion of operating profit potential and a 39% operating margin, which is broadly comparable to mature cloud infrastructure economics: Amazon reported a 37.7% AWS operating margin in Q1 2026, while CoreWeave has pointed to a 25%-30% long-term adjusted operating margin target. The calculation is not perfect, because the 1GW model excludes non-cluster related costs like R&D and SG&A expenses, and assumes primarily vertically integrated development. It does suggest however that a well-utilized neocloud can achieve traditional cloud-like operating margins at scale.

Importantly, the GPU rental market is not stagnant. Agentic AI has driven a surge in demand for GPUs, driving pricing up. H100 one-year rental pricing rose from $1.70 per GPU-hour in October 2025 to $2.35 by March 2026, evidence that older GPUs can appreciate when demand tightens and software unlocks new use cases. Anthropic’s recent deal with SpaceX – priced at an annual run rate of $15 billion for less than a gigawatt of total capacity – suggests willingness to pay per gigawatt could be significantly higher than the above modeling, even for older GPUs.
AI Inference Economics
While AI infrastructure-as-a-service businesses monetize GPU-hours via rentals, AI inference providers monetize model outputs via tokens. A 60% inference service gross margin is a reasonable working assumption: PitchBook estimates frontier-model inference margins around the 50%-60% range depending on provider and model as of February, and more recent sourcing suggesting inference margins of 70%+ as of late April.
For model builders, company level margins can swing significantly based on their compute allocation decisions across revenue generating use cases like usage-based APIs and subscriptions, and unmonetized uses like supporting free users, model training, and R&D. For example, if the entire $14 billion of rented compute is used for inference and inference APIs generate a 60% gross margin, the AI company can support roughly $35 billion of revenue. If only 75% of compute is revenue-generating inference while 25% is training or R&D drag, blended economic gross margin falls to 46.7%. At 50% of total compute monetized, it falls to 20%, as shown below.

Over time we expect inference to grow to a majority of compute allocation, though right now, the model labs are balancing investing in training to stay at the frontier of performance and growing revenues which help fund the acquisition of future training compute. Anthropic’s CFO said in a recent podcast that there is a training compute floor that they will not go below to ensure they stay cutting edge.
A bottoms-up token model gives another lens. A public SemiAnalysis InferenceX benchmark for DeepSeek-V4-Pro on GB200 shows ~1,600 total tokens per second per GPU in an 8k input / 1k output configuration at 32 tokens per second per user. This is a rough proxy for a modern frontier model like Opus 4.7, which sees an output speed of about 40 tokens per second per user and is estimated to be over a trillion parameters in size. At 480,000 GPUs and varying assumptions of average utilization (more important for inference as a service providers who sell by the token compared to multi-year GPU rentals), revenue generation swings significantly from $2.4 billion to nearly $100 billion annually, as shown below.

For reference, actual inference pricing for DeepSeek V4 Pro ranges from $1.90 on the high end, to $0.20 on the low end – a price that appears significantly subsidized from the model’s creator based on the above sensitivity analysis.
Revenue Economics Over Time

Revenue per gigawatt over time tends to rise for two reasons. First, hardware improves. In benchmarking, H100 delivered roughly 900,000 tokens/sec/MW on gpt-oss-120B, while B200 delivered roughly 2.8 million tokens/sec/MW, more than 3x higher power efficiency. The same gigawatt can produce more tokens as rack deployments shift from Hopper to Blackwell.
Second, software improves. SemiAnalysis InferenceX v2 details a litany of algorithmic efficiencies that have driven large Blackwell inference gains over time. In one DeepSeek-R1 example, adding MTP reduced cost from $0.251 per million total tokens to $0.057, a 4.4x improvement. That is not a new data center. It is better utilization of the same silicon.
These software-driven efficiencies explain in part why falling token prices do not necessarily undermine the economics of AI infrastructure. If token throughput per watt rises faster than price per token falls, revenue per gigawatt can net expand. This is compounded by models getting smarter, which unlocks higher value tasks for end users, thus increasing willingness to pay per token as demonstrated by OpenAI effectively doubling pricing per token of GPT 5.5 over GPT 5.4.
Bottom Line
A gigawatt of AI compute is best understood as a factory for intelligence. The facility is expensive, and bottlenecks abound, but the economics of an installed fleet of AI accelerators are strong for both GPU cloud providers and AI model companies. On our working assumptions, a 1GW GB200-class facility could support roughly $14 billion of annual infrastructure rental revenue, while a frontier AI provider can turn that rented compute into inference revenue at attractive margins, generating $35 billion+ annually on compute dedicated to AI inference. We expect these economics to hold, or even improve, so long as the marginal user of AI models continues to value the productivity delivered by digital intelligence.
[1]Hyperscalers refer to large-scale cloud and AI infrastructure companies such as Amazon, Microsoft, Alphabet, and Meta that operate and continuously expand global data center networks.
[2]Neoclouds are AI-native cloud infrastructure providers that specialize in renting GPU compute for large-scale AI training and inference