

The file system is the agent

A few weeks ago, we spoke about how the file system is the most important state management primitive of the AI era. As a result, the file system needs to evolve for this new reality. The first way that we spoke about it evolving was into the place where the agent can run code (for the first time, in a serverless way), eliminating the need for sandboxes as part of the agent stack. It turns out that this isn't quite radical enough. Today, I want to talk about how the file system actually *becomes* the agent itself.
Sandboxes
First, on sandboxes. My prediction is that file systems begin to be seen less as storage libraries for organizing data on a hard drive (think XFS/ZFS), and closer to services which are offered to agents as tools. For example, if you build a file system that exports APIs like getFile, writeFile, searchFiles, and runContainer -- as consumable tools that different AI frameworks can use -- then you actually eliminate the need for agents to have sandboxes, because the file system itself already contains the primitives that are needed to run untrusted code and consistently show the same data on, for example, a web UI.
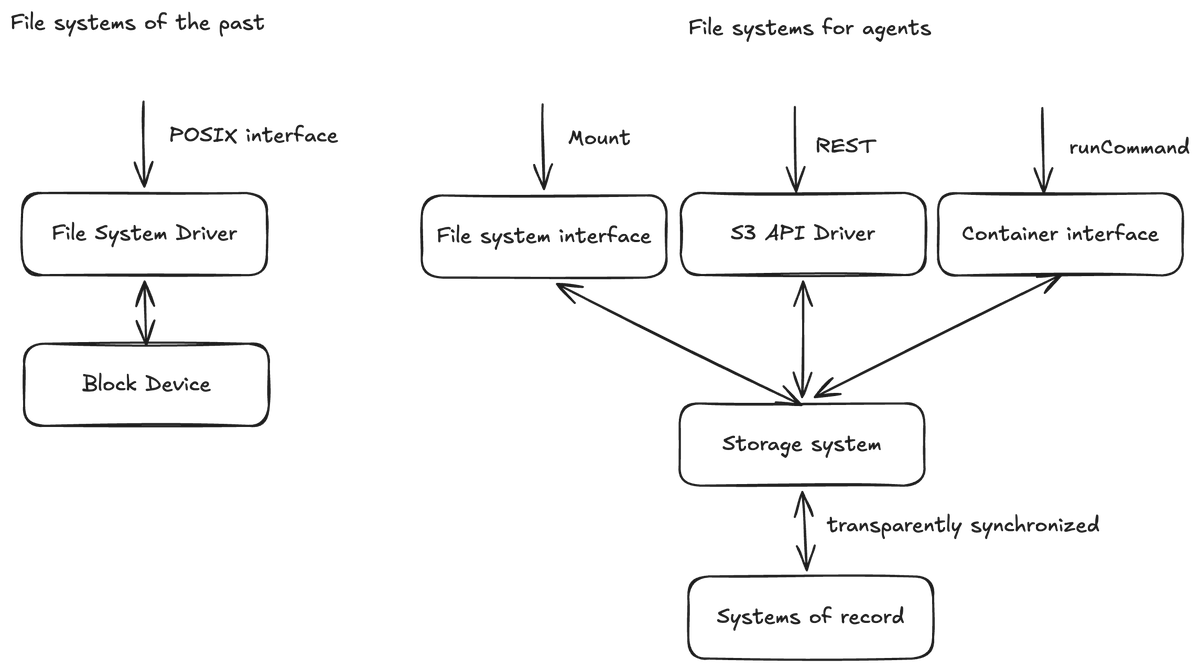
Fundamentally, the problem with thinking about a "sandbox provider" as a separate part of the stack is that it: (a) becomes a resource that you need to manage explicitly [when do you spin it up in the conversation? when do you spin it down?] and (b) it becomes a new data island in your stack, that you need to worry about getting your data into and out of.
This has been a really exciting development, and releasing Serverless Execution has been a breath of fresh air for agent teams who are overwhelmed with the complexity needed to get a production-level agent working.
However, there's a key problem with Serverless Execution that comes up over and over again when we talk to builders: where does the system that actually *invokes* these commands run? Our users have been struggling to slot in other services -- if Archil is the serverless sandbox, does the agent run in Render? Does it run in Exe.dev? Does it run in a different sandbox provider?
We hate for our users to need to deal with these kinds of questions, and so we set out to ask: what does a serverless agent look like. Building a serverless product is harder than a traditional product because you need to abstract away the inputs and outputs of the service, so we had to talk to the people who were building the best agents to get an understanding of what *they* did: folks like Clay, Browserbase, and Wordware.
We're pretty excited about what we found.
What is an agent?
The first thing that you do when you're building an agent is lay out the context that you want that agent to have access to. Agents are the first kind of application which needs access to a breadth of different data sources so that it can synthesize insights across those data sources. This context could be from engineering-owned resources like S3 buckets, but they could also be from other systems of record like Salesforce.
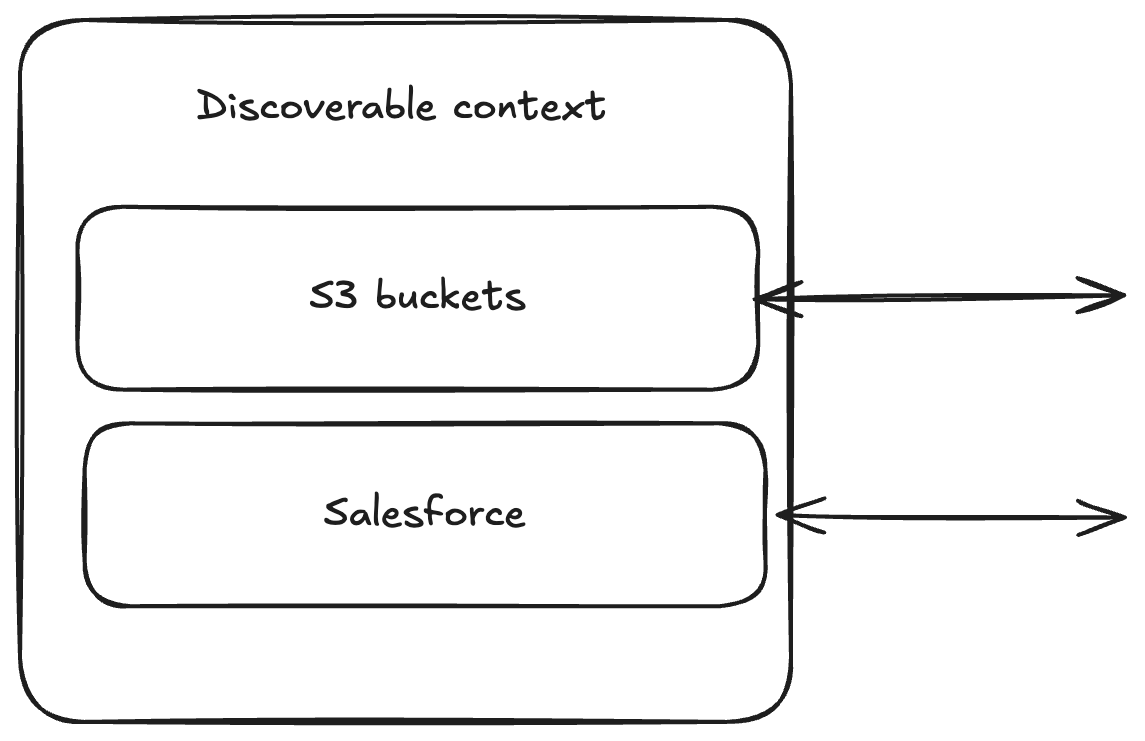
Now, you can think of the "sandbox" primitive as a function that allows us to *manipulate* this context. Executing commands on a Linux box is either used to *extract* information from the context (giving the model the ability to slice and dice it in code before looking at it) or *edit* information in the context (by running things like "sed" over the files that it can see).
The thing that drives the sandbox and manipulates the context is the agent loop, the thing that is calling out the LLM repeatedly asking the LLM what manipulation should happen next.

Even this isn't enough though because something needs to *trigger* the agent loop itself. If you keep pulling the thread, this trigger is usually some kind of user or system interaction. It could be a message in a web-based chat interface, it could be an iMessage, a timer, or a webhook.
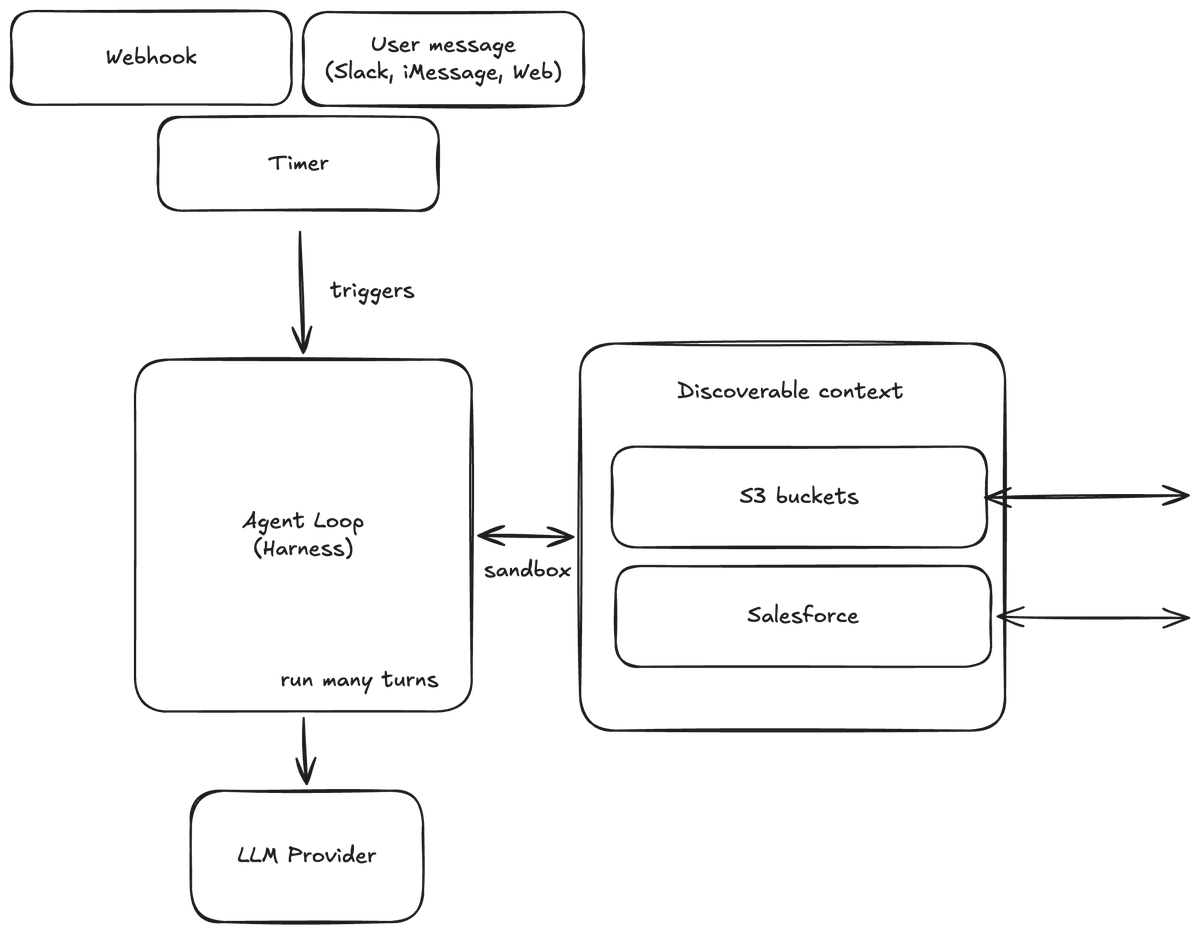
Increasingly, the people that we spoke to told us that they believe that user-driven events (like Slack messages) are going to end up being a small percentage of triggers of the agents in the fullness of time because the quantity of system events (think like automated Datadog alarms, receiving an email, seeing an update from LinkedIn, handoff from another agent) are going to vastly overwhelm the amount of traffic that users can send to these systems.
If you look at this architecture diagram, though, this is a ton of complexity in order to support just one production-level agent! Let's look at each piece in sequence:
This complexity is fine for now, when the majority of agents are being built inside of Silicon Valley at companies which love to build new boxes, but it's going to hamper the ability for AI to roll out over the corporate world to teams who do not want to stitch together a ton of infrastructure just to get something that works.
The solution to these problems is always going to be a managed, serverless solution.
So, what does an ideal serverless agent look like?
I think that it looks something more like this. Let's walk through it piece by piece.

Let's start with the context, since that's the part that's the same between the traditional agent and our new "serverless agent". You clearly need to start by defining what your agent will have access to and setting it up as a "workspace" for it to discover iteratively. This is the role that the file system already fills with agents today.
We can also see how tools like Serverless execution can allow the agent harness to spin up lots of concurrent containers to run Linux in an isolated way that doesn't affect the agent harness itself.
But, there's a third piece -- which is that the agent harness. Today, this traditionally runs on a real, long-running server (whether in the sandbox or outside of it). But, there's not really any reason for that to be the case. If our agent service allows us to automatically get a networked webhook to the agent, then we can define our harness in either a serverless function way (run a single turn and then quit) or a "fluid compute" way (run continuously until you idle long enough to turn off), and serve agent workloads.
Because the file system/context is persistent, we can use that to store conversation history and prompts so that any "restart" of the harness allows us to pick back up exactly where the user left off, without needing to worry about state.
What does this have to do with the file system?
The keystone component of this architecture is having a storage layer that can: keep up with the quantity of agent interactions that are coming, handle running code itself without an external service, and synchronize transparently to systems of record. If you have that component (and I think we do in Archil), then you can envision an agent that runs fully on a file system that looks like this:

There's something magical that happened to me when I realized the deep unlock for generic computation was that the "executables" that you run are just data, no different than the other data stored on your computer.
There is something magical happening in this view of the world as well. The harness itself is just data, it can be stored on the file system -- in the context as well. The conversation history is just data. The connections to systems of record is just data.
Archil today provides what we call the "agent toolset", the minimum set of tools required to work with and manipulate file system context, but soon Archil will have something much cooler.
The ability to indicate where the code to run an agent harness is on your file system, and the ability to invoke it directly -- either through a rest API for integrations, or via a webhook if you want to connect it to other upstream services.
I think that the infrastructure layer is rapidly collapsing into this architecture diagram. Teams are not going to buy point solutions from 10 different providers to run different parts of the agent stack, they're going to collapse into a single service that runs all part of the stack. I think that this flows downstream of the persistent storage layer that holds this context. I think it's a file system that your agents can run on. I think it's Archil.