

Designing eval datasets for LLM applications

This is one piece of a series we’re publishing as part of the Langfuse Academy, where we walk through the full AI engineering lifecycle. If you’re new to the series,The AI Engineering Loop is the best place to start
A short recap of the AI Engineering Loop
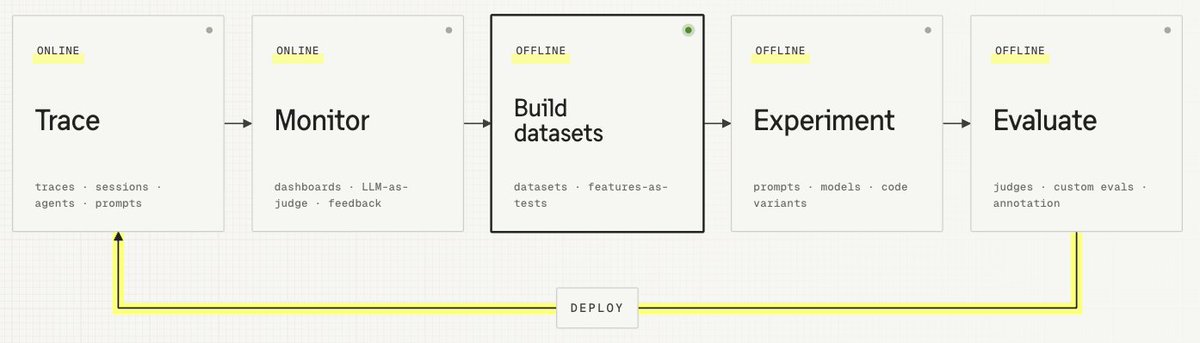
The AI Engineering Loop is how teams continuously improve AI systems. It connects what’s happening in production (tracing, monitoring) to structured iteration during development (datasets, experiments, evaluation). Each shipped improvement produces new data, and teams loop through this process continuously.
You can read more on this here.
How datasets fit into the loop
So far, we've covered the first two steps of the AI engineering loop: tracing your application and monitoring its behavior live. Those give you visibility into what your system is actually doing and give you inspiration for improvement.
Now the question becomes: when you spot something worth improving, how do you test a change before deploying it to production? The next three steps of the loop cover exactly this, and it starts with datasets.
A dataset is a collection of test cases that you run your application against each time you make a change ("an experiment"). Instead of deploying and hoping for the best, you get a repeatable, consistent check across a set of inputs that represent real-world usage.
The dataset item
A dataset is made up of items, each item represents one test case: a situation your application should be able to handle. Generally, an item has three fields:
The three fields of a dataset item

A good mental model:

Common expected output patterns
Whether you need an expected output, and what it looks like, depends on which type of evaluator you use.
Reference-based versus reference-free evaluators
Some evaluators check the output against a predefined expected output (reference-based). Others assess the output without needing a ground truth to compare against (reference-free).
Exact match
The expected output is the literal correct answer. For example:
Reference answer
The expected output is a gold-standard response that shows what a good output looks like. The evaluator can compare the test's output against this example, for instance by checking semantic similarity or whether the key points match.
Evaluation criteria
The expected output is a list of checks or requirements the output should satisfy. For example:
The evaluator checks whether the output meets these criteria.
Nothing
Sometimes no expected output is required at all. If you're just checking whether:
Your dataset items don't need anything other than an input as you will use a reference-free evaluator.
Combination of the above
Because you can run a combination of different evaluators on a single dataset item, a dataset item's expected output field can also contain multiple types of reference data. The expected output is a JSON field, so you can store multiple types of reference data without a problem.
What makes a good dataset
A good dataset mirrors what your system will encounter in production. If passing the dataset gives you confidence before deploying, it's doing its job.
Clear in scope. Each dataset should have a well-defined scope. That can be end-to-end if you treat internal steps as implementation details, or it can target an individual step like retrieval or summarization if that's the part you're trying to improve. You'll likely end up with multiple datasets, each with a clear purpose.

The right size for the workflow. Some datasets are small and fast enough to run on every push as part of your CI/CD pipeline. Others are larger and more comprehensive, and are useful to run periodically but too slow for every minor change.

Where to start
Start with the most concrete examples you have, then expand coverage once you know what you are trying to test.
What comes next
Once you have a dataset, the next step is running your system against it to see how changes affect output quality. This is what experiments are for.