

Loop Engineering Works On Memory

Peter Steinberger(@steipete), recently tweeted: "You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
Boris Cherny, who runs Claude Code at Anthropic, put it differently: "I don't prompt Claude anymore. My job is to write loops." https://thenewstack.io/loop-engineering/
The argument that followed gave the idea a name. Loop engineering.
As Osmani puts it, "loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead." https://addyosmani.com/blog/loop-engineering/ You stop being the one who types the next prompt and start building the thing that does.
This is not theoretical. Cursor pointed hundreds of agents at a single project and let them run: one build went close to a week and produced over a million lines of code across a thousand files, and across these experiments they spent, in their words, "trillions of tokens across these agents toward a single goal" https://cursor.com/blog/scaling-agents. Cherny says that most nights he has "a few thousand" sub-agents doing deeper work overnight https://thenewstack.io/loop-engineering/. The job stops being "type the next prompt" and becomes "design the system that types the prompts, checks the work, and decides what to do next."
Here is what almost every breakdown of loop engineering skips. Those loops do not fail because the model is not smart enough. They fail when it forgets. The binding constraint on a long-running loop is not intelligence, tools, or prompting. It is memory. This article is the proof of that claim, and what to do about it.
What a loop is made of
The progression people have settled on is:
context engineering -> then harness engineering -> then loop engineering.
Every loop moves through the same five stages: discover, plan, execute, verify, iterate.

Osmani lists five components you actually build: automations (/loop, /goal, cron) that trigger discovery, git worktrees that keep parallel agents from colliding, skills (SKILL.md) that carry project knowledge, MCP connectors that let the loop act in real tools, and sub-agents that separate the maker from the checker https://addyosmani.com/blog/loop-engineering/.
Loops come in two shapes, single-agent and fleet, and two temperaments, open (roam freely, burn tokens) and closed (a bounded path with an evaluation gate at each step).
The minimal reference implementation is Geoffrey Huntley's Ralph Loop: while :; do cat PROMPT.md | claude-code; done, which resets the agent's context to a fixed set of files every iteration and hands the stop decision to an external check https://ghuntley.com/ralph/.
That reset is the tell. The design assumes the agent's in-context memory is disposable. Everything that has to survive an iteration lives somewhere else.
Where loops break, and why every break is a memory failure
The failure modes of long-running agents are now well documented, and they rhyme. Every one is the agent losing the plot because something fell out of context.
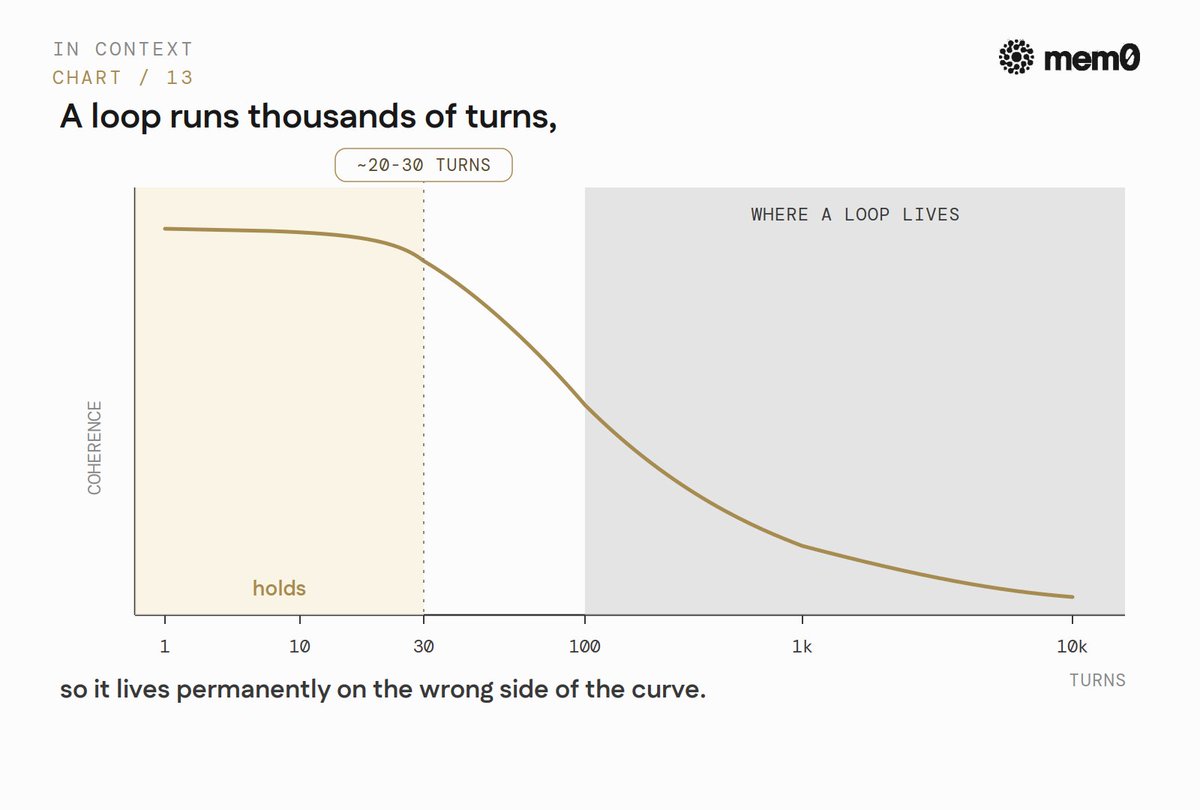
Context rot. Performance degrades as the window fills. The consistent observation is that agents hold coherence for roughly 20 to 30 turns, then start to hallucinate edge facts, misapply earlier assumptions, and double down on conclusions that no longer match reality https://www.mindstudio.ai/blog/context-rot-ai-coding-agents-how-to-prevent. A loop runs for thousands of turns. It lives permanently on the wrong side of that curve unless state is actively moved out.
The Sisyphus Trap. Long pipelines show three linked failures: detail loss (forgetting exact file paths and parameters), goal drift (losing track of iteration counts and stop criteria), and catastrophic forgetting (after enough pruning cycles, the agent loses memory of its own pipeline). The loop keeps rolling the rock and keeps forgetting it already did.
Self-reinforcement. Because a loop re-ingests its own prior output, an early mistake that slips through gets treated as ground truth by every later turn. The error becomes internally consistent and harder to dislodge with each pass. Bad memory does not just lose information; it launders mistakes into facts.
Repeated work. The blunt version: the model forgets, declares "task complete" when it is not, and re-introduces a bug it fixed nine turns ago.
These are not fringe reports.
@cursor_ai, running the most ambitious loops in public, names the same enemy from the other side: "We still need periodic fresh starts to combat drift and tunnel vision," and watched uncoordinated agents fall into "work churning for long periods of time without progress." Their fix for shared state is itself a memory discipline, optimistic concurrency control, where agents read state freely but writes fail if the state changed since they last read it https://cursor.com/blog/scaling-agents.
Read the list again. Drift, forgetting, re-ingesting errors, repeating finished work. No prompt fixes these. They are the same bug: the loop outran its memory.
Why a loop makes memory harder than anything before it
You cannot solve this by stuffing more into context, for three reasons.
First, the window is finite and the automatic fix is lossy. Compaction summarizes history to make room, and it routinely drops detail the agent later needs https://www.mindstudio.ai/blog/context-rot-ai-coding-agents-how-to-prevent.
LongMemEval, the benchmark for sustained chat memory, found commercial assistants drop around 30% on long-term memory tasks relative to short-context performance https://arxiv.org/abs/2410.10813. So the loop faces a forced choice: keep everything and watch quality rot, or prune and lose what it needed.
Second, loops reach the token scale where even good external memory degrades. Standard memory benchmarks cap near 1.5M tokens; a multi-week loop blows past that. Mem0, which published the only memory results at this scale on the BEAM benchmark, scores 64.1 at 1M tokens and 48.6 at 10M https://mem0.ai/blog/what-is-beam-memory-benchmark-the-paper-that-shows-1m-context-window-isnt-enough. The regime loops operate in is the regime where memory systems are weakest, and almost nobody benchmarks it.
Third, recall is not use. MemoryArena showed that systems which near-saturate recall benchmarks still fail when memory has to guide action https://arxiv.org/abs/2602.16313, which is exactly what a loop demands: not "can you recall attempt 12," but "given attempts 1 through 46, what do you do on 47."
And it costs money. Practitioner breakdowns put a single agent loop at 50,000 to 200,000 tokens, a fleet at 500,000 to 2,000,000, and a scheduled loop at millions per week https://x.com/sairahul1.
Context is tokens, and tokens are billed on every call, so carrying stale history forward is a line item, not just a quality risk. Cherny's rule to "keep the context lean enough that the model can still think" and the token bill are the same insight from two sides https://thenewstack.io/loop-engineering/.
How practitioners actually fix it
The fixes are uniform, and they are all memory engineering.

The anchor-file set has stabilized: VISION.md for the goal, CLAUDE.md or AGENTS.md for rules, PROMPT.md for the per-iteration instruction, MEMORY.md for accumulated knowledge, SKILL.md for reusable procedure. Run 47 reads what runs 1 through 46 wrote.
Cobus Greyling calls memory "the durable spine" of a loop and, for any multi-day run, non-negotiable https://cobusgreyling.substack.com/p/loop-engineering.
The frontier turns memory from a passive file into an active step in the loop. Cloudflare's Agent Memory intervenes at compaction: instead of discarding context, it extracts and deduplicates the facts worth keeping, so a weeks-long agent accumulates memory rather than losing it https://blog.cloudflare.com/introducing-agent-memory/.
Research goes further: "Memory as Action" (MemAct) trains the agent to edit its own working memory as a deliberate action mid-task, reporting a 51% cut in average context length with a 14B model matching one roughly 16 times larger, though it is an unreviewed preprint measured on the authors' own benchmark, so read it as directional https://arxiv.org/abs/2510.12635.
The direction is the point: memory curation becomes a move the loop makes.
The bigger loop: memory is what makes it compound
Step back from coding agents and the same structure appears at the scale of the firm.
@satyanadella has been describing a "learning loop on top of models where human capital and token capital compound," where a company turns its workflows and judgment into a system that improves with every use. "This loop becomes the new IP of the firm," he writes. "I think of it as a hill climbing machine. And unlike most assets, it compounds."
What makes it compound is memory. A loop with no durable memory cannot learn; it can only repeat. Nadella's sharpest line doubles as the thesis here: "Without human direction, you have compute running in circles."

Memory is what turns a loop from a circle into a spiral, climbing instead of repeating, because each pass writes something durable the next pass builds on.
How to do it, and where Mem0 fits
If you are building a loop, treat memory as a first-class component, not a MEMORY.md you bolt on at the end. Four rules:
Rule three is where a dedicated layer earns its place, and the cleanest way to wire Mem0 into a loop is its SDK, on the current v3 API, because you already control the loop code https://docs.mem0.ai/platform/quickstart. It is two calls:
Scoping by user_id, agent_id, and run_id keeps a fleet from cross-contaminating https://docs.mem0.ai/platform/quickstart. That is the whole integration: recall, act, store, repeat, with run 47 actually knowing what runs 1 through 46 learned without dragging all of it through context.

If your agent calls memory as a tool rather than your code driving it, you are not limited to the SDK. Mem0 ships an MCP server (https://mcp.mem0.ai/mcp) that Codex and Cursor point at, a Claude Code plugin (/plugin install mem0@mem0-plugins), a plugin for OpenClaw and a provider for Hermes, plus integrations across frameworks like LangGraph and CrewAI https://docs.mem0.ai/integrations/claude-code.
Run it managed at app.mem0.ai
or self-host the open source https://github.com/mem0ai/mem0.
Why it beats a flat file for loops: multi-signal retrieval returns the memory relevant to this iteration rather than the most recent one, facts update in place instead of appending forever, and it is measured at the 1M-to-10M-token scale long loops actually reach https://mem0.ai/blog/what-is-beam-memory-benchmark-the-paper-that-shows-1m-context-window-isnt-enough.
The point is not the vendor. It is that the moment your loop runs longer than one context window, its reliability is a memory problem, and a flat file is not a memory system.
The takeaway
Loop engineering is the headline, but memory is the mechanism. The loop gives an agent persistence across time; memory gives it persistence across forgetting. Get the memory layer right, durable, external, semantic, curated, and a loop runs for days against a real goal and gets better each pass. Get it wrong and no loop design saves you: the agent drifts, repeats finished work, launders its early mistakes into truth, and bills you full price to relive day one.
The term is new and not fully settled. Some call it Agent Loop Design, OpenAI files adjacent ideas under Harness Engineering, and reasonable people call it a rebrand of the agent loop we have had since ReAct in 2022. But the claim underneath survives the naming fight. As agents move from single turns to long-running loops, the hard problem stops being the prompt and becomes the memory. Loop engineering is, underneath, memory engineering.
In Context #13
This blog is part of In Context, a @mem0ai blog series covering AI Agent memory and context engineering.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.