

The Self-Verifying Loop: 300 agents, 4,000 steps, 5 live data feeds on autopilot with Kimi K2.6

Most agent swarms hand you confident garbage. This one checks its own work, throws out what fails, and runs again until every number traces to a source.
The dirty secret of agent swarms is that more agents usually means more confident nonsense.
Point 300 agents at a research job and they will absolutely come back fast. They will also come back with stale numbers, half-invented citations, and three companies that don't exist. Speed was never the hard part. Trust was.
So I stopped treating the swarm as the finish line and made it one stage of a loop. Opus 4.8 plans the work and, more importantly, checks it. The Kimi K2.6 swarm executes. Then Opus verifies every output against its source, throws out whatever fails, and sends those tasks back to run again. The loop only stops when nothing fails.
To test it I gave the loop a job that punishes hallucination harder than anything: analyze 100 companies in the EV market and produce a research-grade report with a comparison matrix, every figure traced to a live source.
A swarm gives you speed. A loop gives you speed you can actually trust. The difference is the verify step, and it changes everything.
The missing piece
Why raw swarms can't be trusted
A swarm with no verifier has exactly one quality setting: whatever the worst agent produced. If 97 agents nail their company and 3 quietly hallucinate a revenue figure, your finished report contains three landmines and looks identical to a perfect one. You won't know which three until it blows up in a meeting.
This is why "just add more agents" plateaus. Volume scales the output and the error count at the same rate. More hands, more mistakes, same lack of anyone checking.
The loop fixes this by making verification a first-class stage with real teeth. Opus 4.8 reads every agent's output back against the live source it claimed to use. A number that doesn't match gets rejected. A citation that doesn't resolve gets rejected. Anything rejected goes back into the queue and runs again. Nothing ships until it survives the check.

The loop
Four stages, running until clean
The whole system is a cycle, not a line. Each half does only what it is best at, and the cycle keeps turning until the verify stage has nothing left to reject.

That fourth stage is the entire idea. A normal swarm runs steps 1 through 3 once and hands you the result, errors and all. The loop refuses to stop while anything is still wrong.
The run
Watching the loop catch its own mistakes
Here is the prompt I gave Opus 4.8. Notice the checklist at the bottom. That checklist is what the verify stage uses to reject bad work later, so it is the most important part of the whole prompt.
Opus planned 100 research tasks, one per company, and handed them to the Kimi K2.6 swarm. The first pass came back in minutes. Then the interesting part started.
On the first verify pass, Opus rejected 12 of the 100 companies. Some had a revenue figure that didn't match the feed it cited. Two cited a source that didn't resolve. One left a margin field empty. None of these would have been obvious in the final report. All of them would have been wrong.
Those 12 went back into the queue with their rejection reason attached. Second pass: 3 still failed. Third pass: zero. The loop stopped on its own, because there was nothing left to reject.

A raw swarm would have shipped those 12 errors and called it done. The loop caught all of them without me reading a single row.
The five live feeds are why verification can be strict instead of vague. Every figure in the report points to Binance, Yahoo Finance, the World Bank, the IMF, or the live stock market. When Opus verifies, it isn't asking the model if it feels confident. It is checking the claimed number against the actual feed. That is the difference between research-grade and confident-sounding.

The bigger picture
This is another DeepSeek moment
Step back from the run, because the strategic picture is the real story.
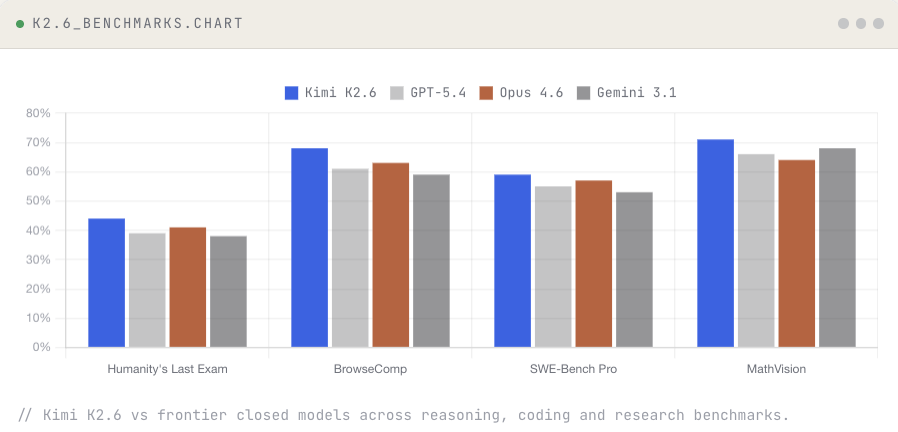
While the closed labs ship single-agent chatbots, an open Chinese lab valued at $20B shipped the swarm that makes a loop like this possible at all. Their open-weight model, Kimi K2.6, currently sits at #1 on the OpenRouter weekly leaderboard. By usage, it is the most-used LLM in the world right now.
And it is strongest exactly where verification matters most:
Run it yourself
The loop, start to finish
You do not need a lab. You need the two halves wired into a cycle, and a checklist strict enough to verify against.

The difference in one frame
Raw swarm
❌ Runs once, hands you the result
❌ Hidden errors ship with the report
❌ Quality equals the worst agent
❌ You audit every row by hand
❌ Confident, unverifiable numbers
Self-verifying loop
✔️ Runs until the verify pass is clean
✔️ Failures caught and rerun automatically
✔️ Quality equals the checklist
✔️ You audit nothing, the loop did it
✔️ Every figure traced to a live source
A swarm gives you speed. A loop gives you speed you can trust. The single-agent era is closing, but the swarm era has a catch nobody mentions: volume without verification is just faster mistakes. The people who win the next one aren't running the most agents. They're running the ones that check their own work.